引言
征程 6 相比于征程 5,在整体架构上得到了升级,相对应的,算法工具链的算子支持也得到了扩充,无论是算子支持的数量,还是 BPU 约束条件,征程 6 都有明显的加强,这就使得过去在征程 5 上无法部署的算法得以在征程 6 上成功部署。本文就以双目深度估计中比较经典的 CGI 算法为例,进行征程 5 和征程 6 算法工具链的编译部署对比。
CGI 导出 onnx
CGI 是一种经典的双目深度估计算法,官方 github 地址为:https://github.com/gangweiX/CGI-Stereo
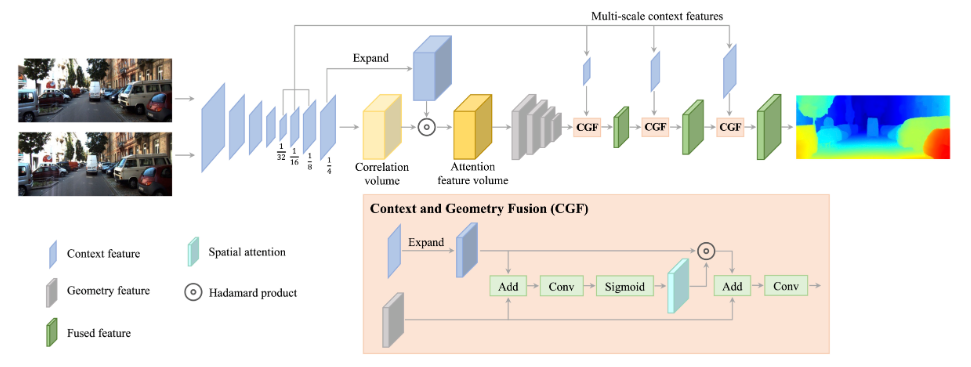
提出了上下文与几何融合(CGF)模块,它能使上下文特征与几何特征有效互动,从而大大提高准确性。该算法还提出了一种新的 cost volume,命名为注意力特征量(AFV),用于编码匹配信息和内容信息。这种精确、实时的立体匹配网络 CGI-Stereo 在 KITTI 基准测试中的表现在当时优于所有其它已发布的实时方法,并显示出比其它实时方法更好的泛化能力。是一种非常经典的双目深度网络。
在将项目 clone 到本地后,我们可以编下如下脚本将网络导出为 onnx。
import torch
import onnx
import argparse
from models import __models__
parser = argparse.ArgumentParser(description='Accurate and Real-Time Stereo Matching via Context and Geometry Interaction (CGI-Stereo)')
parser.add_argument('--model', default='CGI_Stereo', help='select a model structure', choices=__models__.keys())
parser.add_argument('--maxdisp', type=int, default=192, help='maximum disparity')
args = parser.parse_args()
model = __models__[args.model](args.maxdisp)
input1 = torch.randn(1, 3, 352, 640)
input2 = torch.randn(1, 3, 352, 640)
input_names = ["input1", "input2"]
output_names = ["output1"]
torch.onnx.export(
model,
(input1, input2),
"cgi.onnx",
opset_version=11,
input_names=input_names,
output_names=output_names,
)这段代码的主要作用是将 CGI 算法导出为 ONNX 格式。具体解释如下:
导入库:首先,导入了 PyTorch、ONNX、argparse 和一个自定义模块models中的models。torch用于模型操作,onnx用于模型导出,argparse用于解析命令行参数,models是一个包含模型定义的字典。
命令行参数解析:通过argparse.ArgumentParser,定义了两个命令行参数:
--model:选择模型的名称,默认是CGI_Stereo。
--maxdisp:定义最大视差,默认值是 192,用于设置立体匹配中的最大视差范围。
模型初始化:根据用户输入的model和maxdisp参数,从models字典中取出对应的模型构造函数,并用maxdisp参数初始化模型。
生成输入数据:创建两个随机的 Tensor,分别代表左右图像输入,形状为(1, 3, 352, 640),即批次大小为 1,3 个颜色通道,图像尺寸为 352x640。input_names和output_names分别定义了输入和输出张量的名称。
导出为 ONNX 格式:使用torch.onnx.export将 PyTorch 模型导出为 ONNX 格式。输入是刚刚创建的随机图像数据,输出的 ONNX 文件名是cgi.onnx,并指定了 opset 为 11。input_names和output_names确保了输入和输出张量在 ONNX 模型中有明确的名称。
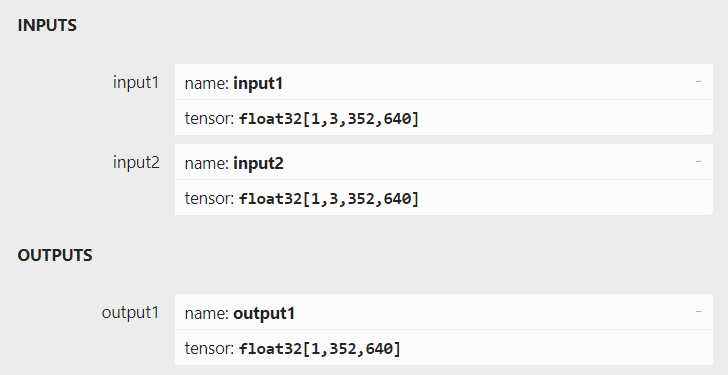
打开导出的 onnx 文件,模型的输入输出信息如下所示。
征程 5 编译
接下来,我们尝试使用征程 5 工具链编译该模型,使用指令如下。
hb_mapper makertbin --fast-perf --model cgi.onnx --model-type onnx --march bayes
转换过程中,便会生成编译器提示的报错信息。

具体来说,就是 Gather 类型的算子,在征程 5 平台上不支持输出的维度超过 4,而这个模型不满足要求,因此无法在征程 5 平台正常编译出来,PTQ 链路的生成物就到 quantized_model.onnx 位置了。
因此,如果想在征程 5 部署这个算法,就意味着需要大改模型。
征程 6 编译
接下来,我们看一下这个 onnx 模型在征程 6 工具链上的表现,编译指令如下。
hb_compile --fast-perf --model cgi.onnx --march nash-m
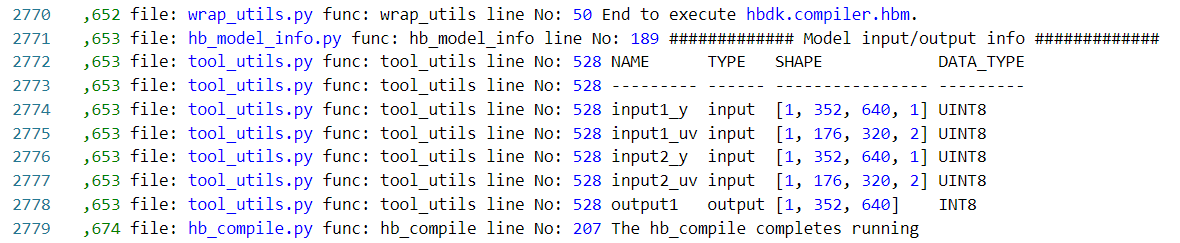
通过编译日志可以看出,这个模型已经编译成功,且两个输入分支自动转换成了 2 组 y/uv 的 uint8 输入。查看 model_output 文件夹,也是要啥有啥,文件齐全~
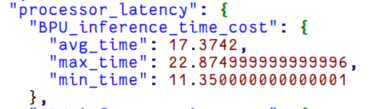
通过 hrt_model_exec 进行板端性能评测,该模型的 BPU 部分推理耗时为 17ms 左右,说明也是可以成功在板端进行推理的,之后就可以继续进行针对这个模型的性能优化和精度优化工作了~
总结
相比于征程 5,征程 6 支持更多算子的高精度配置,如 int16,fp16 等,支持更多的算子运行在 BPU,也对 BPU 约束放宽了条件,大部分算子约束条件减弱甚至没有约束。因此,一些在征程 5 计算平台上难以部署的模型,在征程 6 上往往能有比较好的表现。本文以 CGI 为例进行了说明,更多的算法模型大家可以自行探索~
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
