## 1.引言
当前,地平线 征程 6 工具链已经全面支持了 BEVPooling V2 算子,并与 mmdetection3d 的实现完成了精准对齐。然而,需要注意的是,此算子因其内在的复杂性以及相关使用示例的稀缺,致使部分用户在实际运用过程中遭遇了与预期不符的诸多问题。
在这样的背景下,本文首先会对 BEVPooling V2 的实现进行全方位、细致入微的剖析讲解,让复杂的原理变得清晰易懂。随后,还会通过代表性的示例,来进一步强化用户对该算子使用方法的认知和理解。
2.BEVPoolV2 算子
BEVPoolv2 是 BEVPoolv1 的优化版本,其优化了图像特征到 BEV 特征的转换过程,实现了在计算和存储方面极大的降低。本章首先说明 BEVPoolv2 相对于 BEVPoolV2 的优化点,然后剖析 BEVPoolV2 源码。
### 2.1 先说说 BEVPoolv1
BEVPoolv2 是 BEVPoolv1 的优化版本,其优化了图像特征到 BEV 特征的转换过程,实现了在计算和存储方面极大的降低。BEVPoolv1 (左)和 BEVPoolv2(右) 的示意图如下:
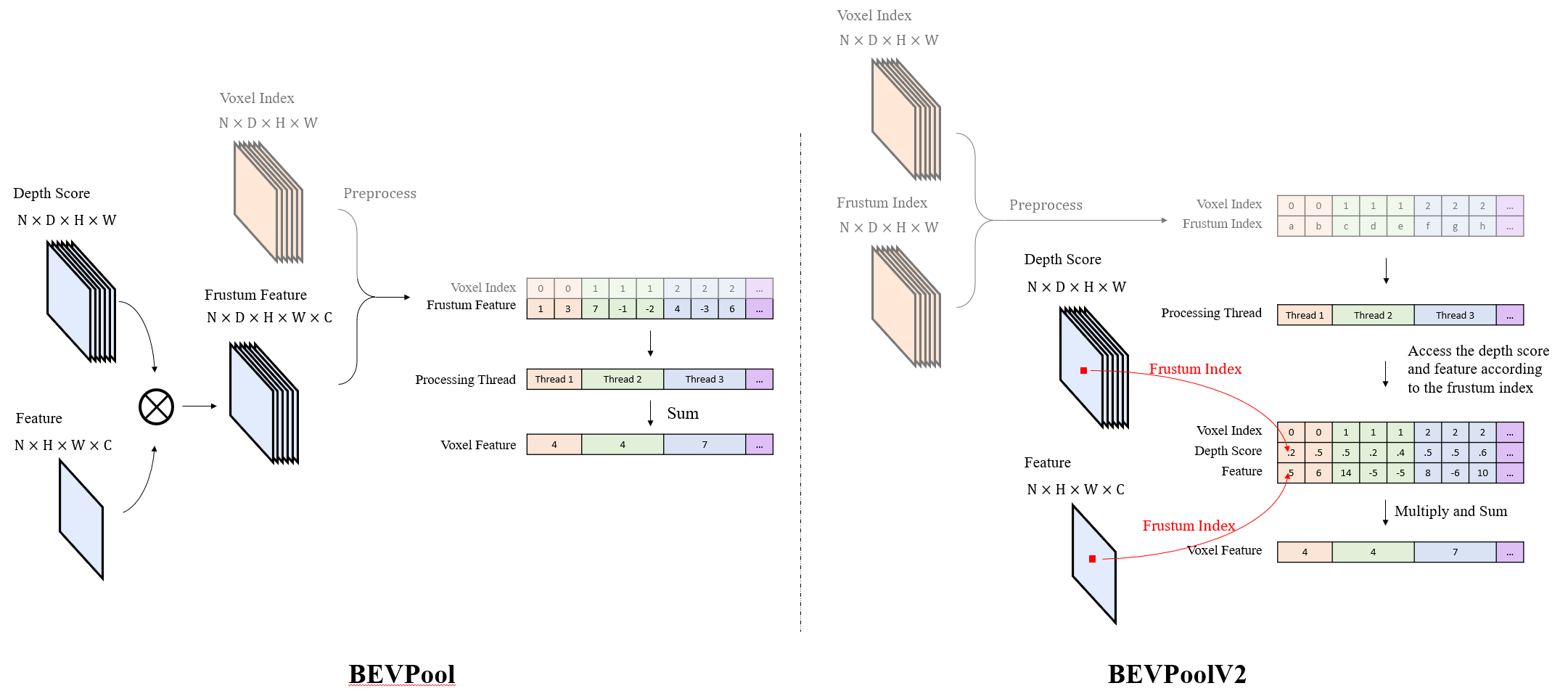 BEVPoolv1 的主要计算流程如下:
BEVPoolv1 的主要计算流程如下:
1. 首先将视锥点云特征 reshape 成 MxC,其中 M=BxNxDxHxW。
2. 然后将 get_geometry()输出的空间点云转换到体素坐标下,得到对应的体素坐标。并通过范围参数过滤掉无用的点。
3. 将体素坐标展平(voxel index),reshape 成一维的向量,然后对体素坐标中 B、X、Y、Z 的位置索引编码,然后对位置进行 argsort,这样就把属于相同 BEV pillar 的体素放在相邻位置,得到点云在体素中的索引。
4. 然后是一个神奇的操作,对每个体素中的点云特征进行 sumpooling,代码中使用了cumsum_trick,巧妙地运用前缀和以及上述 argsort 的索引。输出是去重之后的 Voxel 特征,BxCxZxXxY。
5. 最后使用 unbind 将 Z 维度切片,然后 cat 到 C 的维度上。代码中 Z 维度为 1,实际效果就是去掉了 Z 维度,输出为 BxCxXxY 的 BEV 特征图。
BEVPoolV1 方法具有计算效率相对较高以及融合效果良好的优点,但其缺点也较为明显,即需要对大尺度的视锥体特征进行显式计算、存储及预处理,该视锥体的尺度为(N,D,H,W,C),其中 N 表示相机数量,D 代表深度,H 和 W 分别为特征的高和宽,C 则是特征的通道数。在处理高分辨率图像时,计算量会大幅增加,从而导致推理速度受到限制。
### 2.2 BEVPoolv2
#### 2.2.1 实现思路及性能
BEVPoolv2 的思路如上图右侧所示,其避免了显式计算、存储和预处理视锥体特征,通过离线计算视锥索引和体素索引的对应关系表,在推理过程中固定使用该表,直接根据视锥索引找到对应的图像特征和深度特征进行计算,大大降低了显存占用,并加快了处理速度。其思路可以总结为以下步骤:
1. 离线进行预计算和预处理:体素索引和视锥体索引;
2. 输入深度分数、图像特征;
3. 通过视锥体索引,找到对应深度分数和特征;
4. 相同体素内的视锥体点通过累积求和进行聚合。
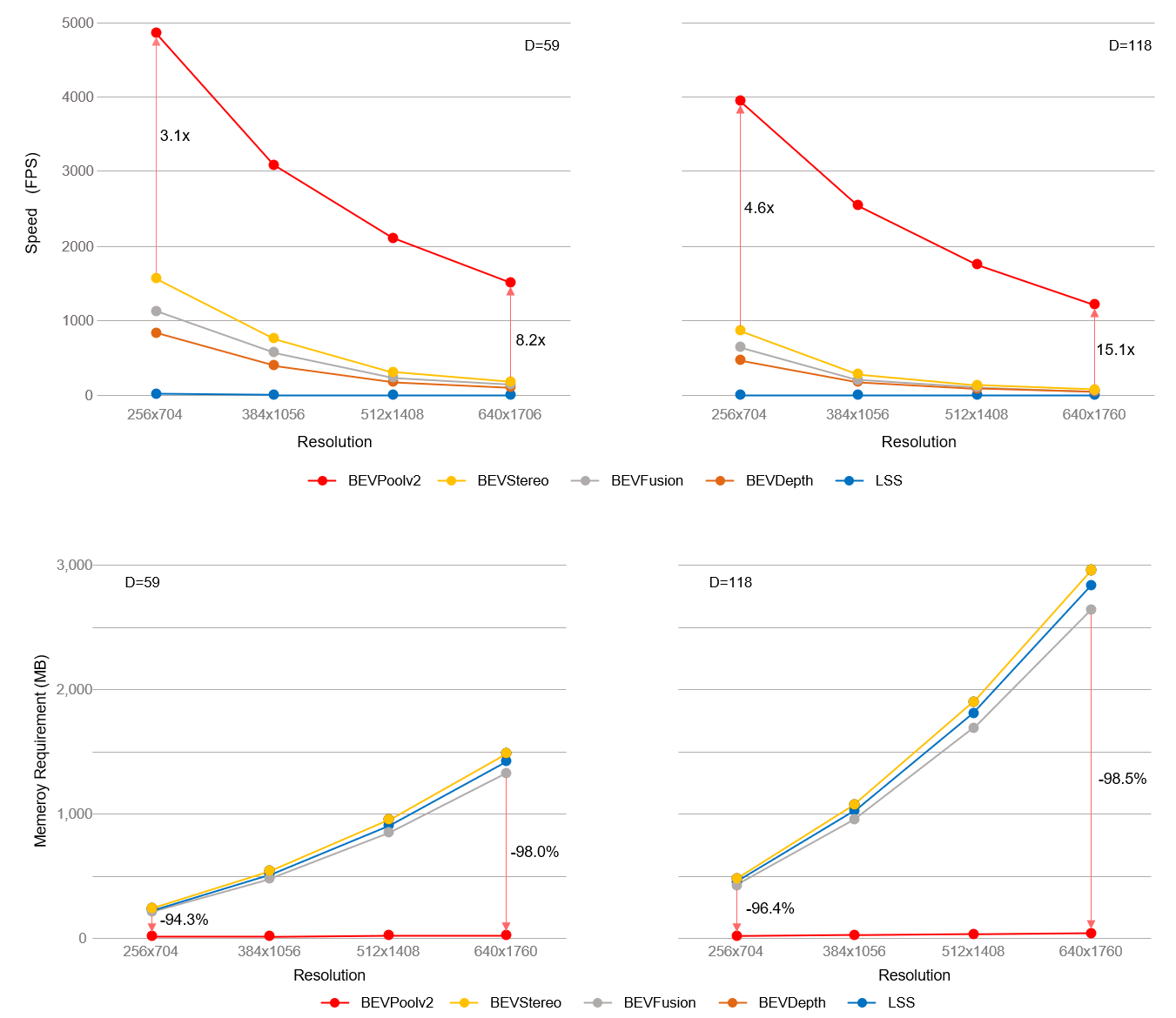
从下图可以看出,BEVPoolv2 在 TensorRT 的推理速度是 Lift Splat Shoot(BEVPoolv1)之前最快实现的 15.1 倍(depth=118),同时,BEVPoolv2 也大大减少了内存消耗。
#### 2.2.2 实现代码解析
**首先根据 depth 数值,构建单个相机的视锥空间**
可以这样形象地去理解:有 DxHxW 个格子,每个格子都有三个元素,分别用来存放这个视锥格子对应的像素坐标 (u, v) 以及它和像平面的距离。
```
#self.frustum 尺寸为D x H x W x 3,
#其中H W的大小与context feat的一致,D 与depth score的Depth 值一致,
self.frustum = self.create_frustum(grid_config['depth'],input_size, downsample)
```
**预计算体素索引和视锥体索引**
**计算每个相机图像对应的视锥在 lidar 坐标系中的位置**
get_lidar_coor 函数将视锥空间的点坐标从图像坐标系转换为 LiDAR 坐标系,经过一系列的坐标变换,包括相机内参、旋转、平移和数据增强补偿。
**step1:**
通过图像增强补偿,去掉视锥点云在图像预处理中因旋转和平移引入的变换,使其回归到未经增强的状态。
```
def get_lidar_coor(self, sensor2ego, ego2global, cam2imgs, post_rots, post_trans,
bda):
"""Calculate the locations of the frustum points in the lidar
coordinate system.
Args:
rots (torch.Tensor): Rotation from camera coordinate system to
lidar coordinate system in shape (B, N_cams, 3, 3).
trans (torch.Tensor): Translation from camera coordinate system to
lidar coordinate system in shape (B, N_cams, 3).
cam2imgs (torch.Tensor): Camera intrinsic matrixes in shape
(B, N_cams, 3, 3).
post_rots (torch.Tensor): Rotation in camera coordinate system in
shape (B, N_cams, 3, 3). It is derived from the image view
augmentation.
post_trans (torch.Tensor): Translation in camera coordinate system
derived from image view augmentation in shape (B, N_cams, 3).
Returns:
torch.tensor: Point coordinates in shape
(B, N_cams, D, ownsample, 3)
"""
# 获取 batch 大小和相机数量
B, N, _, _ = sensor2ego.shape
# post-transformation
#
**第一步:补偿后处理阶段的图像增强(旋转和平移)**
# self.frustum 是视锥空间的点集合,
#初始形状为 (B, N_cams, D, H, W, 3)。
# 通过减去 post_trans(平移补偿)来消除增强中的平移。
#points尺寸 B x N x D x H x W x 3
points = self.frustum.to(sensor2ego) - post_trans.view(B, N, 1, 1, 1, 3)
# 使用 post_rots(旋转补偿)的逆矩阵将点从增强后的空间变换回原始空间。
points = torch.inverse(post_rots).view(B, N, 1, 1, 1, 3, 3)\
.matmul(points.unsqueeze(-1))
```
step2:
将点从相机坐标转换到车辆坐标系(ego 坐标系)。主要通过相机内参矩阵的逆和 sensor2ego 矩阵完成。
```
#
第二步:从相机坐标转换到 ego 坐标系
# 使用深度信息(Z)将点从归一化图像坐标扩展为相机坐标。
points = torch.cat(
(points[..., :2, :] * points[..., 2:3, :], points[..., 2:3, :]), 5)
# 恢复 3D 点坐标
# 计算从相机坐标到 ego 坐标的投影矩阵:
# combine = sensor2ego[:,:,:3,:3](传感器到 ego 的旋转部分)
# × torch.inverse(cam2imgs)(相机内参的逆矩阵)
combine = sensor2ego[:, :, :3, :3].matmul(torch.inverse(cam2imgs))
# 将 combine 投影矩阵应用到点坐标。
points = combine.view(B, N, 1, 1, 1, 3, 3).matmul(points).squeeze(-1) # 形状变为 (B, N, D, H, W, 3)
# 加上 sensor2ego 的平移部分完成坐标变换。
points += sensor2ego[:, :, :3, 3].view(B, N, 1, 1, 1, 3)
```
step3:
将点云坐标应用 Bird's-eye view 的数据增强变换。这一步通常用于生成增强后的 BEV(鸟瞰视图)表示,以便进行进一步的目标检测或场景分割。
```
#
第三步:应用 Bird's-eye view 数据增强(旋转和平移)
# 使用 bda(增强矩阵)的旋转部分对点云进行旋转变换。
points = bda[:, :3, :3].view(B, 1, 1, 1, 1, 3, 3).matmul(
points.unsqueeze(-1)).squeeze(-1)
# 加上 bda 的平移部分完成增强变换。
points += bda[:, :3, 3].view(B, 1, 1, 1, 1, 3)
return points # 返回最终点云坐标
```
代码路径:BEVDET/mmdet3d/models/necks/view_transformer.py
**计算索引关系**
此部分的主要实现函数是`voxel_pooling_prepare_v2` 。函数的主要功能是:
将输入的视锥空间坐标 `coor` 转换为体素(voxel)空间坐标。
生成每个点在深度维度(depth)、特征维度(feature)和 BEV 中的索引。
对体素内点进行排序并划分为连续的区间(interval),为后续基于体素的操作(如 pooling)做准备。
**step1:深度索引**
`ranks_depth` 是用于标识每个点在所有深度栅格中的唯一索引。
```
def voxel_pooling_prepare_v2(self, coor):
B, N, D, H, W, _ = coor.shape # 获取 batch 大小、相机数量、深度维度、高度和宽度。
num_points = B * N * D * H * W # 总的栅格点数。
#
创建深度索引 ranks_depth
ranks_depth = torch.arange(
0, num_points , dtype=torch.int, device=coor.device)
# 一维张量,包含每个深度点的全局索引,形状为 (B * N * D * H * W)。
```
**step2:特征索引**
`ranks_feat` 是将特征索引(以 D 维度复用)扩展到每个深度栅格点,并最终展平成一维。
```
#
创建特征索引 ranks_feat
ranks_feat = torch.arange(
0, num_points // D , dtype=torch.int, device=coor.device)
ranks_feat = ranks_feat.reshape(B, N, 1, H, W)
# 将特征索引扩展到深度维度
ranks_feat = ranks_feat.expand(B, N, D, H, W).flatten()
```
**step3:体素离散化**
`coor` 由连续的坐标值离散化为整数体素坐标。
`grid_lower_bound` 是栅格的最小边界。
`grid_interval` 是体素的间隔大小。
结果是将连续的点云位置转换为体素空间的坐标。
```
#
将 coor 转换为体素坐标
coor = ((coor - self.grid_lower_bound.to(coor)) /
self.grid_interval.to(coor)) # 离散化为 voxel 空间坐标
coor = coor.long().view(num_points, 3) # 转换为整数类型并展平为 (num_points, 3)。
```
**step4:扩展 batch 信息**
将 batch 索引添加到 `coor` 中,构造形状为 `(num_points, 4)` 的张量,其中每行表示 `(x, y, z, batch_idx)`。
```
#
添加 batch 维度
batch_idx = torch.arange(0, B ).reshape(B, 1). \
expand(B, num_points // B).reshape(num_points, 1).to(coor)
coor = torch.cat((coor, batch_idx), 1)
```
**step5:筛选有效体素**
`kept` 是一个布尔张量,用于过滤掉位于体素范围之外的点。体素范围由 `grid_size` 定义。
```
#
筛选有效体素范围
kept = (coor[:, 0] >= 0) & (coor[:, 0] < self.grid_size[0]) & \
(coor[:, 1] >= 0) & (coor[:, 1] < self.grid_size[1]) & \
(coor[:, 2] >= 0) & (coor[:, 2] < self.grid_size[2])
if len(kept) == 0:
return None, None, None, None, None
coor, ranks_depth, ranks_feat = \
coor[kept], ranks_depth[kept], ranks_feat[kept]
```
**step6:生成 BEV 索引**
将每个体素的 `(x, y, z, batch_idx)` 转换为全局唯一的索引 `ranks_bev`。
公式分解:
`coor[:, 3]`:批次索引的偏移。
`coor[:, 2]`:深度索引的偏移。
`coor[:, 1]` 和 `coor[:, 0]`:平面索引的偏移。
```
#
生成 BEV 索引 ranks_bev
ranks_bev = coor[:, 3] * (
self.grid_size[2] * self.grid_size[1] * self.grid_size[0])
ranks_bev += coor[:, 2] * (self.grid_size[1] * self.grid_size[0])
ranks_bev += coor[:, 1] * self.grid_size[0] + coor[:, 0]
```
**step7:排序**
将属于同一体素的点排序,使其在张量中相邻。
```
#
对 voxel 索引排序
order = ranks_bev.argsort()
ranks_bev, ranks_depth, ranks_feat = \
ranks_bev[order], ranks_depth[order], ranks_feat[order]
```
**step8:找到区间起点和长度**
通过对 `ranks_bev` 的相邻元素进行比较,找到每个体素中点云的起点和长度:
`interval_starts`:每个体素中第一个点的索引。
`interval_lengths`:每个体素中点的数量。
```
#
错位操作以找到每个体素的起点
kept = torch.ones(
ranks_bev.shape[0], device=ranks_bev.device, dtype=torch.bool)
kept[1:] = ranks_bev[1:] != ranks_bev[:-1]
interval_starts = torch.where(kept)[0].int()
if len(interval_starts) == 0:
return None, None, None, None, None
interval_lengths = torch.zeros_like(interval_starts)
interval_lengths[:-1] = interval_starts[1:] - interval_starts[:-1]
interval_lengths[-1] = ranks_bev.shape[0] - interval_starts[-1]
```
**返回值**
```
return ranks_bev.int().contiguous(), ranks_depth.int().contiguous(
), ranks_feat.int().contiguous(), interval_starts.int().contiguous(
), interval_lengths.int().contiguous()
```
**ranks_bev** : 一维 tensor,数量与有效的视锥数量一致,每个元素存放 bev 空间中 voxel 的索引值;包含多段连续重复元素,注意:并不是所有 voxel 都被视锥栅格击中,会有大量的空 voxel(fbocc 作者统计将近 50%,所以只有被击中的 voxel 的 index 会留在这里)
**ranks_depth**: 一维 tensor,数量与有效的视锥数量一致,每个元素存放 depth score 的索引值
**ranks_feat**: 一维 tensor,数量与有效的视锥数量一致,每个元素存放 context feat 的索引值
**interval_starts**: 一维 tensor,数量与 voxel 的数量一致,每个元素标识着 ranks_bev feat 的每段"连续片段"的起点
i**nterval_lengths:**一维 tensor,数量与 voxel 的数量一致,每个元素标识着 ranks_bev feat 的每段"连续片段"的长度
代码路径:`BEVDET/mmdet3d/models/necks/view_transformer.py`
#### `voxel_pooling`计算
预计算体素索引和视锥索引后,将其与 backbone 输出的 context_feat 和 depth score 一起输入到`voxel_pooling_v2`函数中进行计算。相关代码如下所示:
```
def voxel_pooling_v2(self, coor, depth, feat):
# 准备体素池化所需的索引和区间信息
ranks_bev, ranks_depth, ranks_feat, \
interval_starts, interval_lengths = \
self.voxel_pooling_prepare_v2(coor)
# 如果没有点位于预定义的 BEV 感受野内
if ranks_feat is None:
print('warning ---> no points within the predefined '
'bev receptive field')
# 创建一个占位的全零张量,其形状与期望的 BEV 特征张量一致
dummy = torch.zeros(size=[
feat.shape[0], # 批次大小 B
feat.shape[2], # 通道数 C
int(self.grid_size[2]), # 网格 Z 轴的大小
int(self.grid_size[0]), # 网格 X 轴的大小
int(self.grid_size[1]) # 网格 Y 轴的大小
]).to(feat) # 保持张量设备与输入 feat 一致
# 将占位张量的 Z 维展开为 2D 格式
dummy = torch.cat(dummy.unbind(dim=2), 1)
return dummy # 返回占位张量作为输出
# 调整特征张量的维度顺序,变为 (B, C, D, H, W) -> (B, C, H, W, D)
feat = feat.permute(0, 1, 3, 4, 2)
# 定义 BEV 特征的目标形状
bev_feat_shape = (
depth.shape[0], # 批次大小 B
int(self.grid_size[2]), # 网格 Z 轴的大小
int(self.grid_size[1]), # 网格 Y 轴的大小
int(self.grid_size[0]), # 网格 X 轴的大小
feat.shape[-1] # 特征维度 C
)
# 调用
bev_pool_v2
函数进行 BEV 特征池化
bev_feat = bev_pool_v2(
depth, feat,
ranks_depth, ranks_feat, ranks_bev,
bev_feat_shape, interval_starts, interval_lengths
)
# 如果需要折叠 Z 维度
if self.collapse_z:
# 展开 Z 维度,将其变为 2D 格式
bev_feat = torch.cat(bev_feat.unbind(dim=2), 1)
# 返回最终的 BEV 特征张量
return bev_feat
```
代码路径:`BEVDET/mmdet3d/models/necks/view_transformer.py`
`voxel_pooling`的核心函数为`bev_pool_v2`,其核心功能为:
**前向传播**:
`bev_pool_v2_kernel`:实现 pooling 的核心操作。将 3D 空间中的深度和特征映射到 BEV 表示中。
`bev_pool_v2`:封装了内核的调用,提供方便的接口。
**反向传播**:
`bev_pool_grad_kernel`:计算 pooling 操作的梯度,包括对深度图和特征图的梯度。
`bev_pool_v2_grad`:封装内核调用,用于梯度计算。
**优化特性**:
使用 CUDA 内核并行计算,充分利用 GPU 的计算能力。
通过索引 (`ranks_*`) 和区间信息 (`interval_starts`, `interval_lengths`) 高效定位需要处理的数据。
核心函数`bev_pool_v2_kernel`实现为:
```
global
void bev_pool_v2_kernel(int c, int n_intervals,
const float *
__restrict__
depth,
const float *
__restrict__
feat,
const int *
__restrict__
ranks_depth,
const int *
__restrict__
ranks_feat,
const int *
__restrict__
ranks_bev,
const int *
__restrict__
interval_starts,
const int
restrict
interval_lengths,
* float*
restrict
out) {
int idx = blockIdx.x * blockDim.x + threadIdx.x; // 获取全局线程索引
int index = idx / c; // 当前处理的 interval 索引
int cur_c = idx % c; // 当前处理的通道索引
if (index >= n_intervals) return; // 超出 interval 数量则退出
int interval_start = interval_starts[index]; // 获取当前 interval 的起始位置
int interval_length = interval_lengths[index]; // 获取当前 interval 的长度
float psum = 0; // 用于累计加权和的变量
const float* cur_depth; // 当前点的深度指针
const float* cur_feat; // 当前点的特征指针
for (int i = 0; i < interval_length; i++) { // 遍历 interval 内所有点
cur_depth = depth + ranks_depth[interval_start + i]; // 当前点的深度值
cur_feat = feat + ranks_feat[interval_start + i] * c + cur_c; // 当前点的特征值
psum += *cur_feat * *cur_depth; // 计算加权和
}
const int* cur_rank = ranks_bev + interval_start; // curt_rank是一个指针,
cur_rank 是该元素对应的voxel idx
* float*
cur_out = out + *cur_rank * c + cur_c; // 对应的输出位置
*cur_out = psum; // 将累计结果写入输出
}
```
代码路径:`BEVDET/mmdet3d/ops/bev_pool_v2/src/bev_pool_cuda.cu`
# 参考链接
BEVPoolv2 论文:https://arxiv.org/abs/2211.17111
mmdet3d 实现代码:https://github.com/HuangJunJie2017/BEVDet/blob/6fd935a084d403d097d5e2f18a45568e11bf3dc0/mmdet3d/ops/bev_pool_v2/bev_pool.py#L95
https://zhuanlan.zhihu.com/p/557613388
https://zhuanlan.zhihu.com/p/675738148
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
