目前在 GPU 上训练的模型大部分都是浮点模型,即参数使用的是 float 类型存储。而地平线 BPU 架构的计算平台使用的是 int8 的计算精度(业内计算平台的通用精度),能运行定点量化模型。
地平线 征程 6 算法工具链(以下简称工具链)作为专业量化工具,是一套完整的边缘计算平台算法落地解决方案,可以帮助您把浮点模型量化为定点模型,并在地平线计算平台上快速部署自研算法模型。当需要对量化后的参数进行调整时,又可以将量化方法分为训练后量化(PTQ)和量化感知训练(QAT)。
其中训练后量化 PTQ 是使用一批校准数据对训练好的模型进行校准,将训练过的FP32模型直接转换为定点计算的模型,过程中无需对原始模型进行任何训练。只对几个超参数调整就可完成量化过程,过程简单快速,无需训练,此方法已被广泛应用于大量的端侧和云侧部署场景,我们优先推荐您尝试 PTQ 方法来查看是否满足您的部署精度和性能要求 。如下即为 PTQ 流程所需数据和基本步骤:

本文章聚焦训练后量化(PTQ),展示 PTQ 基本流程以及和上一代计算平台工具链之间的使用差异。
02 PTQ量化&编译
征程 6 PTQ 的使用方式、yaml 配置参数等均和 征程 5 保持一致,详细说明可见用户手册《6.2 PTQ 转换工具》,下文将对其中部分功能点的使用方式做具体说明。

2.1 校准数据
当前版本已支持在 yaml 文件中配置 色彩转换(如 nv12—>bgr)和 归一化(mean & scale),同时在数据保存上,也支持复用征程 5 上使用的 bin 格式(np.tofile)。 与征程 5 不同的是,征程 6 的 PTQ 需要手动对校准数据做归一化。 另外,征程 6 也支持使用 np.save 将数据保存为 npy 格式。
2.2 前处理节点
征程 6 PTQ 前处理节点的配置方式和征程 5 保持一致,可以完全复用。需要注意的是:
征程 5 的前处理节点在 *_original_float.onnx 阶段就已经插入;
征程 6 只在 *_quantized.bc 和 *.hbm 模型上插入,各阶段 onnx 模型推理时的输入数据则完全一致。另外,征程 6 也提供 HBRuntime 推理库,使用同一套接口推理各阶段 onnx 模型 以及 HBIR(*.bc) 模型,详细说明可参考用户手册的HBRuntime推理库章节。
2.2.1 input_type_rt
当前版本已支持配置 input_type_rt: nv12:
input_parameters:
input_type_rt: 'nv12' # 配置为nv12或gray时,input_source默认自动选择为pyramid
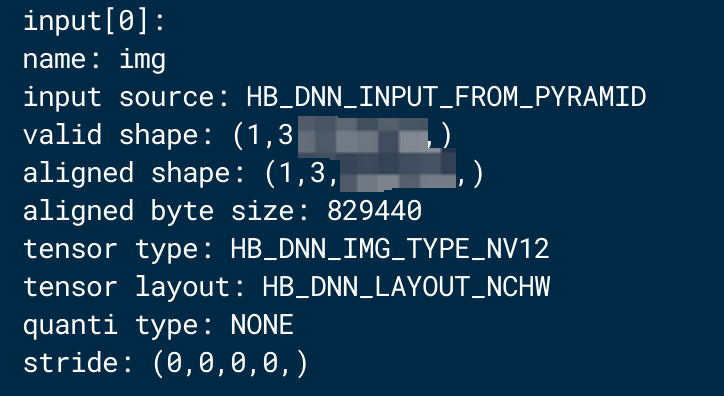
以单输入 nv12模型为例,在 X86 环境使用 hb_model_info 工具查看 *_quantized.bc 的模型信息,其输入节点已经被拆分成 y 和 uv 两个分量;进一步在 qemu 环境使用 hrt_model_exec model_info 工具查看 *.hbm 的模型信息,其 input_source 为 pyramid 类型。
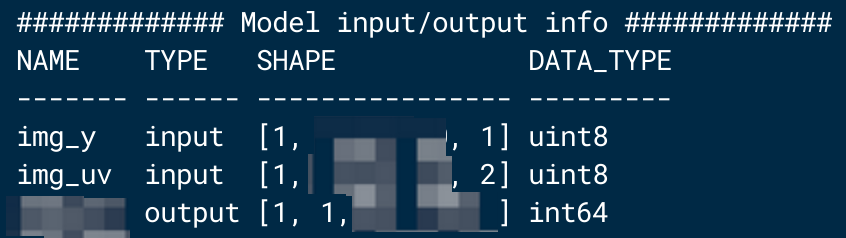
| *_quantized.bc | *.hbm |
hb_model_info *_quantized.bc -v 可以生成其可视化 onnx,如下图所示,已插入前处理节点
2.2.2 数据归一化
目前 PTQ 已支持配置归一化参数,其使用方式和 征程 5 保持一致,值得注意的是:校准数据准备时手动在代码中加入了归一化操作,如果此处配置了归一化参数,为推理准备数据如果参考校准数据准备流程是要移除校准数据准备中的重复操作:
input_parameters:
norm_type: 'data_mean_and_scale'
mean_value: 127 127 127
scale_value: 0.0078125 0.0078125 0.0078125
2.3 Resizer输入
目前 PTQ 已支持配置 input_source 来指定是否为 resizer 输入,参考如下:
input_parameters:
input_type_rt: 'nv12'
compiler_parameters:
input_source: {'input0':'resizer'} #resizer仅支持input_type_rt配置为nv12或gray
环境打印模型信息,确认已成功编译为 resizer 模型:
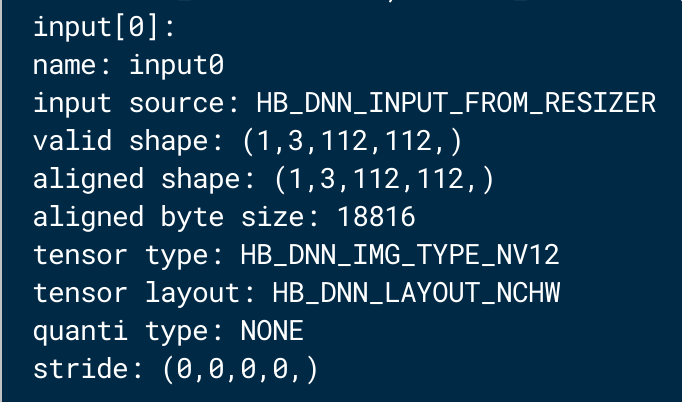
2.4 Batch输入拆分
当前 Alpha 版本在部署端,暂不支持 Batch>1 的 Pyramid/Resizer模型 以连续地址输入数据进行推理,因此需要将 batch 输入显式地拆分成 batch 份并提供独立地址。当前 PTQ 链路拆分模型 batch 输入的方式包含如下几种:
拆分方式一:
适用场景:适用于任何模型
正常转换模型,并基于生成的 ptq_model.onnx,调用 hbdk python api 进行 batch 拆分后重新编译模型,参考代码如下:
import onnx
from hbdk4.compiler.onnx import export
from hbdk4.compiler import convert, compile
ptq_onnx = onnx.load("./*_ptq_model.onnx")
ptq_bc = export(ptq_onnx)
# 将该模型第一个输入节点按batch维度(0)做拆分,方式同QAT
func = ptq_bc.functions[0]
# 依据部署需要,维护一个独立地址部署的输入节点名称列表,或index列表
# 输入节点名采用上一节的方式进行了自定义修改
batch_input = ["input_name1"]
for input in func.inputs[::-1]:
for name in batch_input[::-1]:
if name in input.name:
input.insert_split(dim=0)
# ps:
# 1.insert_split会导致节点数变多,因此建议从后往前拆
# 2.就算batch=1,该接口也会尝试拆分,会导致输入节点的name增加 “_0” 后缀
quantized_bc = convert(ptq_bc, "nash-e")
compile(
quantized_bc,
march="nash-e",
path="./*.hbm"
)
拆分方式二:
适用场景:当前版本仅适用于 单输入 模型,暂不支持多输入模型 直接使用 separate_batch 拆分 batch(要求原始模型为单输入且 batch=1,并配合使用input_batch配置 batch 数):
input_parameters:
input_batch: 16
separate_batch: True
拆分方式三:
适用场景:在 DL 框架内拆分 batch 输入后重新导出 ONNX 模型
2.5 删除指定节点
当前版本已支持删除指定名称/类型的节点,其支持删除的算子类型和 yaml 配置方式和征程 5 保持一致。 需要注意:与 征程 5 不同,征程 6 没有提供 **hb_model_modifier** 工具用于修改模型节点。
model_parameters:
remove_node_type: Quantize;Transpose;Dequantize;Cast;Reshape;Softmax
#remove_node_name:
03 性能评估
性能测试可以分为静态测试和动态测试两种模式或阶段。
3.1 静态评估
静态评估是编译器根据模型的结构和计算平台架构通过静态的分析预估出的模型 BPU 部分的性能情况。需要注意因为评估需要计算平台深层的架构信息做支撑,目前静态评估的结果仅 BPU 部分,不含 CPU/DSP 等性能情况。如果想获取全面的性能数据还需要通过动态评估。 静态评估是通过地平线提供的 hb_compile 工具进行的,该工具集成了模型编译与性能分析的功能。在模型转换编译完成后,会在yaml文件配置的 working_dir 路径下生成编译器预估的模型BPU部分的模型静态评估文件:model.html(可读性更好)和model.json。用户可通过他们了解模型的静态评估结果。 另外,如果用户需要,也可以通过 python 组件的hbdk4.compiler主动进行性能评估,参考代码如下:
from hbdk4.compiler import hbm_perf
hbm_perf("model.hbm")
3.2 动态测试
动态评估是通过测试工具hrt_model_exec实际在板端运行被测试模型最终获取性能结果的过程。因为测试过程就是模型推理过程的真实在线,因此是对模型推理过程所需的系统依赖的一个全面评估,该过程有效弥补了静态评估仅针对 BPU 部分测评的不足。 hrt_model_exec工具的具体使用方法可以参考用户使用手册 和 部署部分的文章,这里不单独赘述。
04 精度评测
精度评测是通过一批测试数据集(包含真值)、推理脚本以及结果后处理程序获取优化前后模型的精度信息,进而了解模型从浮点模型量化为定点模型过程中带来的精度损失情况。需要用户了解的是后量化方式是基于几十或上百张校准数据实现的模型从浮点到定点转换过程,无论是数据的规模还是模型参数的表达宽度都与原始模型训练过程有很大的差距,精度损失在一定程度上是不可避免地。地平线转换工具经过大量实际生产经验验证和优化,在大部分情况下可以将精度损失保持在1%以内,这在业界已经是很牛的存在。 通过模型编译过程我们了解*_quantized_model.bc是过程的产物之一,虽然最后的hbm模型才是将部署到计算平台的模型,考虑到方便在Ubuntu开发机上完成精度评测,我们一般通过bc模型文件来进行精度评测过程。模型推理参考代码如下: 下方示例代码不仅适用于quantized模型,对original和optimized等onnx模型同样适用(替换模型文件即可),根据模型的输入类型和layout要求准备数据即可。
import numpy as np
# 加载地平线依赖库
from horizon_tc_ui.hb_runtime import HBRuntime
# 准备模型运行的输入,此处`input.npy`为处理好的数据
data = np.load("input.npy")
# 加载模型文件,根据实际模型进行设置
# ONNX模型
sess = HBRuntime("model.onnx")
# HBIR模型
sess = HBRuntime("model.bc")
# 获取输入&输出节点名称
input_names = sess.input_names
output_names = sess.output_names
# 准备输入数据,根据实际输入类型和layout进行准备,配置格式要求为字典形式,输入名称和输入数据组成键值对
# 如模型仅有一个输入
input_feed = {input_names[0]: data}
# 如模型有多个输入
input_feed = {input_names[0]: data1, input_names[1]: data2}
# 进行模型推理,推理的返回值是一个list,依次与output_names指定名称一一对应
output = sess.run(output_names, input_feed)
当然,这里主要描述了模型精度分析基本流程和推理代码,如果评估发现结果不符合预期,可以参考用户手册中的 PTQ 模型精度调优 章节的内容尝试调优,其中 PTQ 精度debug 工具 征程6 与征程 5 使用方式一致,精度分析推荐流程也一致,具体请参考社区文章 精度验证及调优建议流程。主要区别就是征程 6 平台的性能评估过程是通过(*_quantized_model.bc)hbir 格式
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。


