1.1 什么仿真?
仿真是使用其它相似的系统来模仿真实的需要研究或使用的系统,其所遵循的基本原则是相似性原理。仿真从框架上涉及到两个系统:1)被仿的系统:需要研究或使用的系统;2)仿真出来的系统:在用户侧视角与被仿的系统有一定相似性。 注意:这里的系统是个抽象的概念,可以是软件,也可以是硬件,还可以是复杂的综合事件。在 征程6 开发平台中,仿真的对象为“开发板及其上的系统”。
1.2 为什么要仿真?
仿真在不同行业不同背景下的的目的是不同的,这些目的包括但不限于:
设计组装自动控制系统。
评价目标系统性能和功能。
为目标系统设计扩展功能和组件。
在 征程6 开发平台中,仿真系统可以为我们提供下列便捷:
缓解开发工作对开发板硬件的依赖 物理开发板的 CPU 是 ARM 的,其系统指令也是 ARM 平台的,其上应用程序的代码需要经过 arm 编译器的处理。在缺少物理开发板的情况下,经过接口仿真在开发服务器(X86平台)上实现了与 ARM 平台侧相似(因为系统及计算架构有异存在些许差异的情况是可能的,但差距一般很小)的功能。因为仿真接口和ARM平台侧接口在设计上保持了完全一致性,所以所开发的应用程序在经过不同编译器处理后即可生成的平台适用的目标程序并加以运行。对于开发而言,开发者在没有获得物理开发板前提前开始功能开发和验证工作,从仿真的 X86 平台切换真实的 ARM 平台时,只需要对所开发的代码修改编译器和运行时库便可以快速完成从仿真到真实平台的转换过程;对于用户学习而言,OE 所提供的 ARM 侧程序也可以通过改编译器和运行时库在开发服务器上加以使用。
避免多人共享同一物理开发板时带来的环境冲突问题 物理开发板属于临界资源,其上的系统版本在某一时刻是确定而且是唯一的。如果不同人在开发时所依赖的系统版本不同,那么得不到系统版本满足的开发人员便无法进行开发工作。而仿真环境是通对通过 docker image 的版本加以区分的,其独立且可以通过 DOCKER 容器构建多个相同或不同的仿真环境,如此一来,不同开发者对系统版本的依赖便可得到解决。
数据回灌仿真
为代码调试提供便利 在开发环境中同时存在了业务源代码、编译的目标程序以及 X86 平台调试工具 gdb。可以对业务代码逐行进行裆部调试,加速功能 bug 的排查。
1.3 仿真系统的优缺点
仿真系统包括方便快捷、成本低廉、工作效率高等诸多优点,但是每一个事物都有其两面性,仿真系统也存在一定缺点。在 征程6 开发平台中,仿真系统的缺点包括:
性能一致性 因为特定业务场景需要,真实开发板在设计时引入了特定加速硬件以加速计算过程,而仿真所依赖的开发机一般是为通用计算而设计的普通 PC 机,并不包含真实开发板所具备的加速硬件。所以这里的仿真更多是功能上的仿真。当然,显卡作为普通计算机组件在很多 PC 机上是配备了的,同时显卡也是AI加速的主要器件之一,在接口仿真实现时可以通过显卡加速。然而这里仍然有两个方面需要考虑:1)显卡的加速效果与显卡配置相关,同时即使配置上去了是否可以达到真实的开发板上特别设计过的加速硬件也很难说。2)仿真有很多个,其加速代码的质量和开发时间也是逐步进行的,所以同样硬件条件下随着工具链版本迭代加速效果也可能是不同的。
功能一致性 因为仿真系统和被仿真系统在计算架构、操作系统等方面存在差异,同样的数据输入在经过处理后得到的输出结果可能存在些许差异,但差距一般很小。
开发投入 因为业务代码的最终运行环境(arm架构)和 仿真环境间的差异,需要在开发阶段构建两套编译脚本: X86 平台编译脚本 For 仿真; arm 平台编译脚本 For 最终的板端部署。
系统特性约束 仿真的本质是 X86 平台上“模仿”出接口以实现在 ARM 平台上的功能。在 X86 仿真平台下无法使用 ARM 平台下特有的功能和指令,如 Neon。因此,功能仿真过后在最后的实车部署阶段,还是需要依赖工程的深度优化(Neon 加速等),还会涉及对齐等工作。
2. 仿真在 征程6 计算平台的实现2.1 仿真框架概述
在 征程6 开发平台中,仿真功能是通过地平线统一异构计算框架 HUCP(Horizon Unified Computing Platform)来实现的。相对于 征程5 的 DNN 预测库,HUCP 支持自定义算子(Plugin)并 新增了数学计算库(FFT、BLAS等)、CV 库等的封装, 进行了功能和边界的扩展以提供计算图全图(视频通路 + 前/后处理 + 多模型串街 + 自定义计算)表达的能力,支持将全图一起送入下游编译。
注:为支持全图表达能力,在 Torch 开发环境新增 FLAP 和 LEAP 两套自定义计算组件,支持通过 DSL、Numba、Triton 等算法友好的 Python 编程方式,添加模型前/中/后的自定义计算,包括:
在 Pyramid、GDC 等硬件 IP 功能上拆分封装出的各种 OP(LEAP)
CPU/ VPU 上实现的自定义计算(前/后处理,自定义算子等)(FLAP)
2.2 仿真实现原理
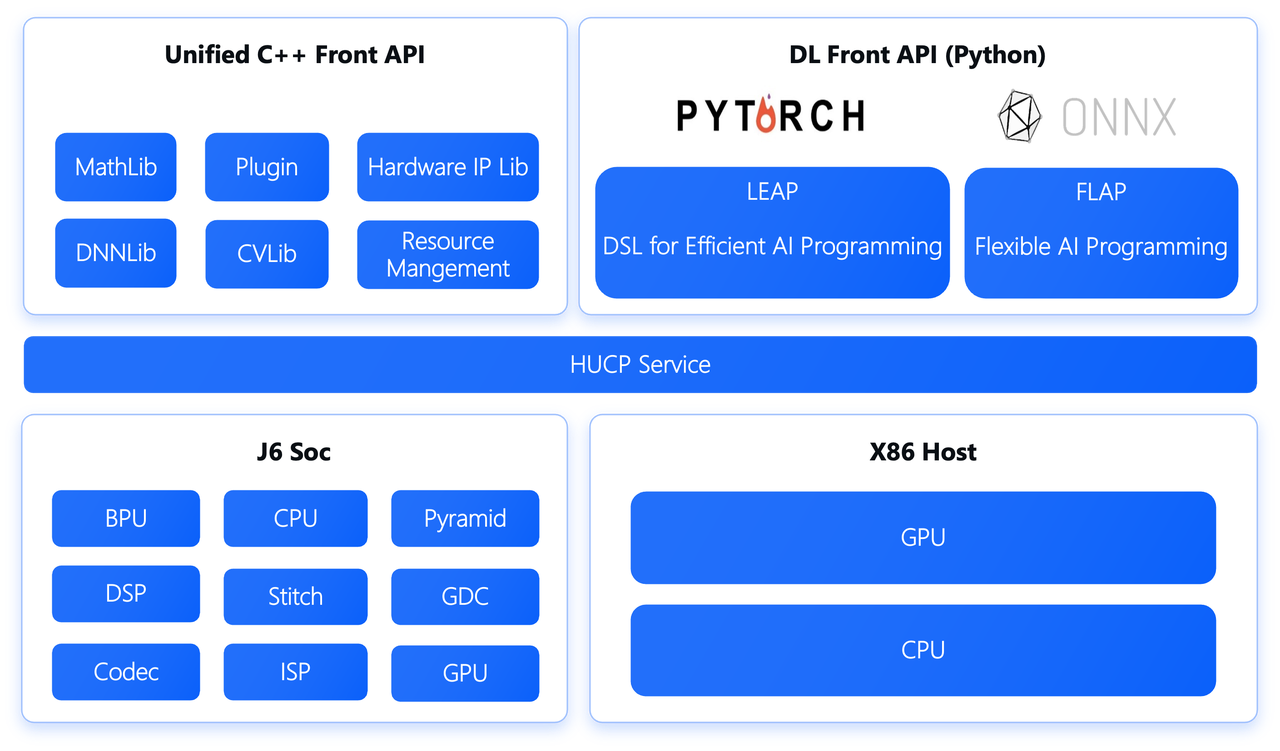 上图 是 征程6 开发平台感知部署框架的构成,可以看出 HUCP 介于应用程序和运行平台之间,是应用程序和运行平台之间的“中间件”。对上,HUCP 为上层应用开发设计和提供了一套统一的应用程序编程接口(API);对下,隐蔽不同 CPU 架构在接口实现上带来的差异,不同架构的运算平台调用各自的系统接口对 HUCP 提供的编程接口进行实现和编译以生成不同架构的动态链接库供编译器连接时调用。
上图 是 征程6 开发平台感知部署框架的构成,可以看出 HUCP 介于应用程序和运行平台之间,是应用程序和运行平台之间的“中间件”。对上,HUCP 为上层应用开发设计和提供了一套统一的应用程序编程接口(API);对下,隐蔽不同 CPU 架构在接口实现上带来的差异,不同架构的运算平台调用各自的系统接口对 HUCP 提供的编程接口进行实现和编译以生成不同架构的动态链接库供编译器连接时调用。
3. 仿真哪些东西
仿真功能依赖于统一异构计算框架 HUCP,而 HUCP 所提供的应用程序编程接口在实现时不仅调用了 BPU、CPU、DSP 等常规硬件资源,同时也包含对 Pyramid、GDC、Stitch、Codec 等视频通路上的硬件 IP(不包含非计算的 camera 接入部分)资源的利用。在 征程6 SoC 上这些硬件是真实存在的,在 X86 平台下,通过接口的 X86 平台实现对这些硬件进行了仿真,从而透明化了不同平台间接口调用的差异。对于应用程序开发者而言,在面向接口编程的思想指导下仅需在编译阶段选择对应平台的编译工具和编译库即可。
4. 功能如何使用4.1 基础使用环境准备
仿真功能作为算法工具链发布套件的一部分,其所依赖的环境已经集成在工具链发布(v3.0.12之后)的 docker 镜像中,仿真功能基础示例(horizon_j6_open_explorer_xxx-py38_20240430/samples/ucp_tutorial/dnn/basic_samples/code/00_quick_start)也包含在工具链每次发版的 OE 包中。因此跟使用AI工具链其他功能一样,在开始使用仿真功能之前,需要先参考工具链使用手册 load 算法工具链的 docker 镜像,然后根据镜像构建映射了 OE 包的用户容器。 用户容器启动后便可参考基础示例体验仿真功能了.
注:详细的工具链使用手册 docker 基础环境准备和 docker 使用,请参考。
4.2 业务代码编写
UCP 为应用程序开发者提供了统一的业务编程接口,在面向接口编程的思想指导下透明化了不同平台间接口调用的差异。因此,在业务代码构建上,不同运行平台的业务代码并无差别,开发者可将注意力集中在业务逻辑之上,待业务代码构建完成后开发者仅需在编译时选择对应平台的编译工具和编译库即可完成编译进行业务测试。 注:如果想在基于 ARM 架构的开发板平台上通过 ARM 平台下特有的功能和指令(如 Neon)加速业务处理过程,同时基于仿真调试业务逻辑,可通过编译宏区别平台分别进行编程,由此带来的工作量和两个环境下数据对齐问题需要用户自己评估。
4.3 编译脚本构成
仿真平台和被仿真平台的 CPU 架构和指令集是不同的,所以说使用的编译器和运行时库也会存在差异。业务代码构建完成后,进行编译时,需要针对不同的目标运行平台选择正确的编译器和运行时库,下下述为X86 仿真平台和 ARM 目标开发板平台在部署工程实现时依赖库和脚本间的差异(来自 OE 包基础实例程序horizon_j6_open_explorer_xxx-py38_20240430/samples/ucp_tutorial/dnn/basic_samples/code/00_quick_start)。
依赖库差异 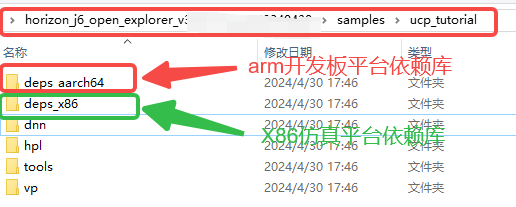
SHELL 编译脚本差异 
CMakeLists.txt 脚本中 ARM&X86 差异 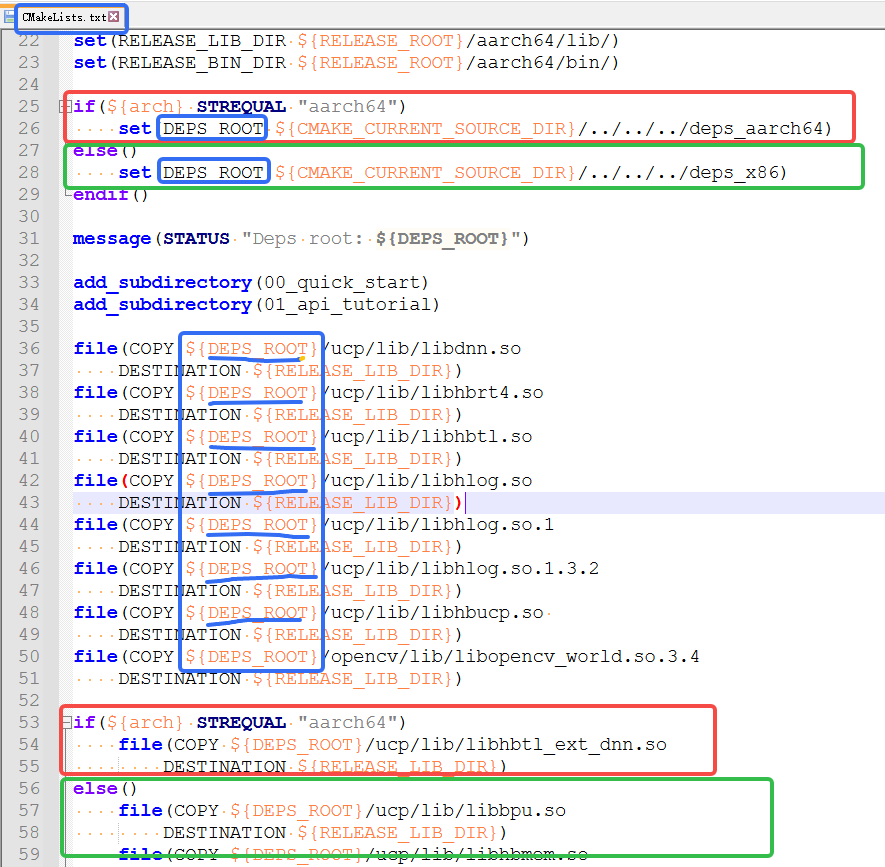
5. 仿真案例5.1 快速入门
该示例代码展示了 x86 仿真平台和 arm 开发板平台的基本脚本逻辑和编译逻辑,用户可以以此参照为自己的工程添加仿真构建逻辑。 
5.2 扩展工程案例
OE 包原 ai_benchmark 示例为方便向开发者提供参考模型后处理逻辑,构建了插件式“数据处理+模型推理+推理结果处理与展示”业务流框架。为方便开发者使用仿真功能进行自有模型的后处理代码调试,最大限度复用已有的插件式雨雾流程框架,我们对原有的 ai_benchmark 工程进行了部分修改并添加了仿真编译脚本,开发者可以参考扩展工程中 fcos 的后处理代码逻辑(类继承关系)构建适配自己模型的后处理文件并在配置中加以引用。因扩展工程中编译脚本是自动进行新增文件索引和编译的,用户只需要将自己扩展的后处理代码文件保存至与 fcos 的后处理代码文件统计的 method 目录(注意头文件和源文件分别存放)下进行编译即可,无需进行他们脚本代码的开发。
扩展工程相对于 OE 包中原 ai_benchmark 示例代码有如下差异:
保留了原 ai_benchmark 示例代码中所有的插件式框架代码,包括推理数据准备、模型推理代码以及与后处理、输出四者间的调度逻辑。
删除了源代码中大部分模型的后处理逻辑,仅保留了 fcos 的部分以作示例。
添加仿真编译脚本并对原有的 CMakeLists.txt 进行变动同时对测试运行脚本 env.sh 微调以适应仿真场景需要。
用户可以参考 fcos 的后处理逻辑可针对自己的模型构建后处理进行功能仿真验证。
6. 其他说明6.1 与 征程5 仿真对比
J征程5 仿真功能提供的是一套基于 GPU 环境的 QAT 定点模型(红框1)推理方式,但因为该模型位于编译之前,所以端侧 runtime 数据类型的变化并不能同步体现在 x86 端。而相同的场景下,征程6 使用新一代 HBDK4 工具链对其进行了标准化,如下图所示,编译环节会同时产出一个上板模型和一个可 GPU 推理的仿真模型(红框2),SoC 和 x86 端可以使用完全相同的 API 无感地加载和推理这两个模型。因此,在 征程6 工具链中,算法同学能够在 x86 环境下快速、便捷地完成原型验证、回灌仿真等工作,节约大量算法/工程对齐的开销,后续也能丝滑地迁移至 SoC 环境(只需替换模型文件,基于交叉编译工具重新编译工程即可),从而极大地提升了生产开发效率。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。