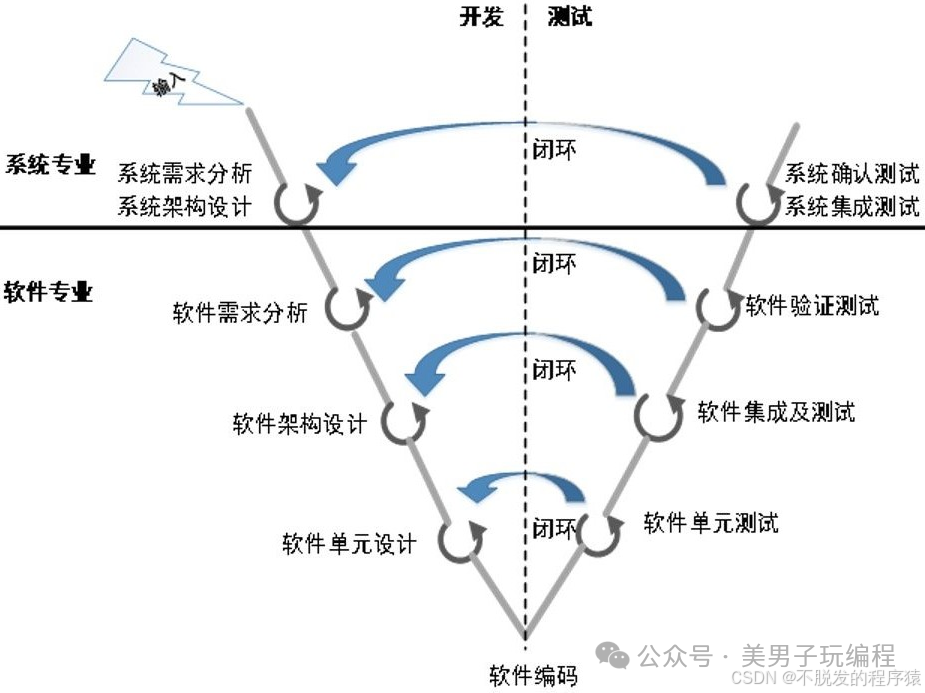
1.引言
本文将介绍地平线基于公版的双目深度估计算法 StereoNet 做的优化设计。首先介绍了双目深度估计的原理以及双目点云和 Lidar 点云的对比,然后由公版 StereoNet 的介绍切入到地平线参考算法的针对性优化,最后对可视化结果进行了解读。
2.双目深度估计原理
2.1 基本假设
假设双目系统是标准形式,即:
两相机内参数相同,即焦距、分辨率等参数一致;
两相机光轴平行;
成像平面处于同一水平线;
假设以左相机坐标系为主坐标系,也就是说两相机只存在 X 轴方向上的平移变换。
2.2 几何法
P 是待测物体上的某一点,
O_R 与 O_T 分别是两个相机的光心,
p、p':点 P 在两个相机感光器上的成像点,相机的成像平面经过旋转后放在了镜头前方
f 为相机焦距,B 为两相机中心距,Z 为我们想求得的深度信息。
公式中,焦距 f 和摄像头中心距 B 可通过标定得到,因此,只要获得了视差 d=X_R−X_T,就可以计算出深度 Z。
视差是同一个场景在两个相机下成像的像素的位置偏差。
2.3 相机参数推导法
由基本假设可以可知,左右相等,且左右相机只存在 X 轴方向的平移运动。那么有:
相机模型和各种坐标系介绍:https://blog.csdn.net/qq_40918859/article/details/122271381
2.4 双目点云和激光雷达点云的比较
参考链接:https://www.zhihu.com/question/264726552
感知距离
双目模型在近处比较有优势(几十米),在远处的时候类似于单目,而 Lidar 感知距离可以达到 200m+(210-250)。
点云**密度**
双目的点云比 Lidar 要稠密。双目模型估计出的深度是像素级别的,camera 分辨率越大,点云就越稠密。而 Lidar 的采样点覆盖相对于场景的尺度来讲,具有很强的稀疏性。
精度
Lidar 是主动方法,双目是被动方法,而且双目是根据模型估计视差计算出的深度,存在一定的标定、安装误差以及深度失真问题,所以其输出的深度信息的精度是不及 Lidar 的,但是需要注意的是 Lidar 受天气影响更大。
在某些场景下,深度图边界容易失真,错误主要体现在以下三方面。
缺失(Missing):边界缺失是指高质量 RGB 图像中存在真实对象边界,但在深度图中这些边界丢失了;
虚假(Fake):是指在深度图中存在对象边界,但在 RGB 图像中不存在真实边界的情况;
错位(Misaligned):RGB 图像和深度图中均有真实边界,但彼此没有很好的对齐;
黑夜不 work
3.
3.1 基本情况
dataset: SceneFlow
Input shape: 540x960
精度:
3.2 网络结构
3.2.1.特征提取
采用共享权重的孪生神经网络提取双目图像的特征,使用 K 个下采样 block 进行高层特征提取;
3.2.2.Cost volume 构建
Cost volume 是在双目匹配中用于衡量左右视图的相似性的张量。
特征下采样之后,在低分辨率下计算 cost volume,输出的 shape 是
Cost volume 的计算方式为 concat,即将左右视图的特征图在通道维进行 concat:
def build_concat_volume(
self,
refimg_fea: Tensor,
targetimg_fea: Tensor,
maxdisp: int,
) -> Tensor:
"""
Build the concat cost volume.
Args:
refimg_fea: Left image feature.
targetimg_fea: Right image feature.
maxdisp: Maximum disparity value.
Returns:
volume: Concatenated cost volume.
"""
B, C, H, W = refimg_fea.shape
C = 2 * C
tmp_volume = []
for i in range(maxdisp):
if i > 0:
tmp = self.c_cat[i].cat(
(refimg_fea[:, :, :, i:], targetimg_fea[:, :, :, :-i]),
dim=1,
)
tmp_volume.append(self.c_pad[i](tmp).view(-1, 1, H, W))
else:
tmp_volume.append(
self.c_cat[i]
.cat((refimg_fea, targetimg_fea), dim=1)
.view(-1, 1, H, W)
)
volume = self.c_cat_final.cat(tmp_volume, dim=1).view(
B, C, maxdisp, H, W
)
return volume
通过 concat 获得的 cost volumes 不包含有关特征相似性的信息,因此在后续模块中需要更多参数来学习相似度函数。
maxdisp 是预先设定的最大视差,也就是模型能预测到的最大视差。
3.2.3.Cost volume 优化和计算视差
获得 4D cost volume,使用 conv3d 进行优化。
然后基于优化后的 cost volume 获得低分辨率下的视差图。cost volume 优化后得到 Nx1xDxHxW 大小的特征图,然后使用 softmax 得到在每个视差值下的概率。
相关代码:
# Optimize cost volume to obtain low disparity
for f in self.filter:
cost0 = f(cost0)
#优化视差
cost0 = self.conv3d_alone(cost0)
cost0 = cost0.squeeze(1)
#转化为概率
pred0 = self.softmax(cost0)
#乘以对应的视差值
pred0 = self.dis_mul(pred0)
pred0 = self.dis_sum(pred0)
3.2.4.refine 到原图
利用层次化微调模块来逐渐对视差图进行修复,补充高频信息以实现边缘保留。具体做法是对粗糙的低分辨率视差图进行上采样,并根据粗糙视差图和原始左视图 rgb 输入预测出一个残差图,加到该视差图中获得一个细化视差图。
具体操作:
首先将深度图和 RGB 图像拼接(Concatenate),得到的拼合张量再经过一个 3x3 的卷积操作得到 32 通道的表示张量,之后再通过 6 个 残差块(Residual Block)的操作,每个残差块由于卷积、批正则化(Batch Normalization)、矫正线性单元(Leakey ReLU)等操作;为了扩大网络,在每个残差块中使用了扩张(Dilate)卷积的操作,最后经过一个 3x3 的卷积,得到最后的单通道深度图。
SteroNet 由左右图的特征经过连接得到一个 4D cost volume, 之后利用 3D 卷积进行代价聚合得到最终的视差图,这种方式导致其计算成本十分高昂。
4.StereoNetPlus
4.1 总体结构
4.2 模型优化点
4.2.1 特征提取
使用 MixVarGENet+FPN 来提取双目图像的多尺度特征;
4.2.2 Cost Volume 构建和优化
采用 AANet 的思想,基于相关性构建多尺度 cost volume,并进行尺度内和跨尺度融合,最终输出 1/8 原图尺度下的 cost volume。
AANet 网络
作者通过设计两个有效且高效的成本聚合模块:自适应同尺度聚合模块(Adaptive Intra-Scale Aggregation)
和自适应跨尺度聚合模块(Adaptive Cross-ScaleAggregation)来实现成本聚合。并且使用特征相关性而不是 concat 的方式构造多尺度 Cost Volume。
cost volume 构建
使用 1/8,1/16, 1/32 原图尺度下的特征图构造多尺度 cost volume;
def build_aanet_volume(self, refimg_fea, maxdisp, offset, idx):
B, C, H, W = refimg_fea.shape
num_sample = B // 2
tmp_volume = []
#maxdisp:最大预测视差
for i in range(maxdisp):
if i > 0:
#计算左右视图特征的相关性
cost = self.gc_mul[i + offset].mul(
refimg_fea[:num_sample, :, :, i:],
refimg_fea[num_sample:, :, :, :-i],
)
#取均值
tmp = self.gc_mean[i + offset].mean(cost, dim=1)
#padding
tmp_volume.append(self.gc_pad[i + offset](tmp))
else:
#计算左右视图特征的相关性
cost = self.gc_mul[i + offset].mul(
refimg_fea[:num_sample, :, :, :],
refimg_fea[num_sample:, :, :, :],
)
#取均值
tmp = self.gc_mean[i + offset].mean(cost, dim=1)
tmp_volume.append(tmp)
volume = (
self.gc_cat_final[idx]
.cat(tmp_volume, dim=1)
.view(num_sample, maxdisp, H, W)
)
return volume
ISA
在视差非连续时,边缘位置总会有一圈连续的错误匹配值,为了缓解这种问题,使用 3 个残差模块 BasicResBlock 对每个尺度的 cost volume 进行聚合。
CSA
双目图像进行下采样后,在相同的 patch 尺寸下,纹理信息将更具鉴别性,所以跨尺度成本聚合算法中引入了多尺度交互。最终的 cost volume 是通过对不同尺度的成本聚合结果进行自适应组合得到的,公式如下:
下面将对公式中的 3 种情况进行说明:
优化效果
由于没有使用 conv3d,所以相对于基础版模型,性能有了一定的提升。
基础版模型:720P 输入下,单核 fps 18.22, latency:54.9ms, 960*540 输入下精度 1.12(浮点)
优化版模型:54.9ms ->16.59ms epe: 1.12->0.948
4.2.3 计算粗略视差
使用融合后的 1/8 尺度下的 cost volume 计算小图视差。
# Fusion costvolume as AANet
aanet_volumes = aanet_volumes[::-1]
for i in range(len(self.fusions)):
fusion = self.fusions[i]
aanet_volumes = fusion(aanet_volumes)
#1/8尺度:1X24x68x120(24=192/8)
cost0 = self.final_conv(aanet_volumes[0])
# Obtain low disparity and unfold it.
#转化为视差概率
pred0 = self.softmax(cost0)
#乘以对应的视差值范围[0,23]
#24=192/8
pred0 = self.dis_mul(pred0)
#sum求和,获得1/8尺度下的粗略视差
pred0 = self.dis_sum(pred0)
#unfold操作:使用2x2conv替代
#pred0_unfold shape:1x4x68x120
pred0_unfold = self.unfold(pred0)
对粗略视差进行上采样时,会用到邻域点的特征,所以用了一个 unfold 的一个操作,先把这个视差从那个小图上面取出来,取出来过后,然后上采样,然后再跟 featuremap 预测出来的权重去相乘,最后会得到一个最终的时差值。这种做法会减少 refine 的过程中的计算量。
这里为了进一步节省耗时,使用 conv2x2 替换 unfold 操作:
class UnfoldConv(nn.Module):
"""
A unfold module using conv.
Args:
in_channels: The channels of inputs.
kernel_size: The kernel_size of unfold.
"""
...
def forward(self, x: Tensor) -> Tensor:
"""Perform the forward pass of the model."""
#将尺寸pad到(1,1,69,121)
x = self.pad(x)
#conv代替unfold
x = self.conv(x)
return x
4.2.4 refine 原图
使用左图特征预测出权重,然后和上采样到原图尺寸的粗略视差相乘,这样就得到了最终视差。
特征提取:使用 MobileNetV2 作为主干特征提取器,因为它具有轻量级的特性,并构建了一个 U-Net 方式的上采样模块,在每个尺度层次上都有长跳跃连接;
构建 cost volume:在左右图像的 1/4 尺度上提取的特征图构建相关层,以输出 D/4×H/4×W/4 cost volume;
cost volume 聚合:使用了 3D 卷积的沙漏结构,但减少了通道数量和网络深度以降低计算代价,在每一个模块之后加入引导代价体激励;
Guided Cost volume Excitation (GCE):利用从图像中提取的特征图作为成本聚合的指导,以提高精度
GCE
CoEx 使用 DeconvResModule 融合 P1/2、P1/4、P1/8 的左图特征,从而获得原始图像分辨率下的视差权重。
将预测到的权重和上采样到原图大小的粗略视差相乘:
将双线性插值优化为最近邻插值;
此部分在模型的后处理部分进行。
4.3 计算深度并可视化
4.3.1 计算深度
根据获得的视差计算像素深度:
#基于几何法,根据模型预测的视差计算深度
def process_outputs(model_outs, viz_func, vis_inputs):
preds = model_outs.squeeze(0).cpu().numpy()
f = float(vis_inputs["f"])
baseline = float(vis_inputs["baseline"])
img = vis_inputs["img"]
#f:焦距;baseline:相机平行光轴之间的距离
#preds:预测视差
depth = baseline * f / preds
preds = viz_func(img, preds, depth)
return None
4.3.2 可视化
可视化结果从左至右为:left 左图、right 右图、disparity 视差图、根据视差计算的 depth 深度图;
视差图中的颜色代表:颜色越红,视差值越小;颜色越蓝,视差值越大;
深度图中的颜色代表:颜色越红,对应的像素深度值则越小;颜色越蓝,对应的像素深度值则越大;
视差图到深度图的计算原理可参考中的几何法,相应代码可以参考 config 文件中的 process_outputs 函数。
参考链接
https://blog.csdn.net/sinat_29819401/article/details/129382207
https://blog.csdn.net/wjinjie/article/details/122303148
https://github.com/meteorshowers/X-StereoLab
https://zhuanlan.zhihu.com/p/302888864
https://blog.csdn.net/gy1153441419/article/details/126709760
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。